Gli internal¶
3 differenze principali¶
Iniziamo con tre caratteristiche di git con le quali dovresti familiarizzare.
- Non c’è un server: il repository è locale. La gran parte delle operazioni è locale e non richiede l’accesso alla rete. Anche per questo troverai git incredibilmente veloce.
- Il progetto è indivisibile: git lavora sempre con l’intero codice sorgente del progetto e non su singole directory o su singoli file; con git non c’è differenza tra committare nella directory principale o in una sotto-directory. Non esiste il concetto di checkout di un singolo file o di una singola directory. Per git il progetto è l’unità indivisibile di lavoro.
- git non memorizza i cambiamenti dei file: git salva sempre i file nella loro interezza. Se in un file di 2 mega modificassi un singolo carattere, git memorizzerebbe per intero la nuova versione del file. Questa è una differenza importante: SVN memorizza le differenze e, all’occorrenza, ricostruisce il file; git memorizza il file e, all’occorrenza, ricostruisce le differenze.
4 livelli di operatività offline¶
Sull’assenza di un server ho un po’ mentito: come ti ho già detto e come vedrai più avanti, git è un sistema peer-to-peer, e riesce ad interagire con dei server remoti. Nonostante questo, resta sostanzialmente un sistema locale.
Per capire quanto questo possa avvantaggiarti, prova a vederla così: quando il codice sorgente di un progetto è ospitato su un computer remoto hai 4 modi per editare il codice
- Lasci tutto il codice sul computer remoto e vi accedi con ssh per editare un singolo file
- Trovi il modo di ottenere una copia del singolo file per poterci lavorare più comodamente in locale e lasci tutto il resto sul computer remoto
- Trovi il modo di ottenere una copia locale di un intero albero del file system e lasci il resto della storia dei commit sul computer remoto
- Ottenieni una copia locale dell’intero repository con tutta la storia del progetto e lavori in locale
Avrai notato due cose.
La prima, che SVN e i sistemi di versionamento ai quali sei probabilmente abituato operano al livello 3.
La seconda, che i 4 sistemi sono elencati in ordine di comodità: in linea di massima, quando il materiale è conservato sul sistema remoto il tuo lavoro è più macchinoso, lento e scomodo. SVN ti permette di fare il checkout di un’intera directory proprio perché così ti risulti più comodo passare da un file all’altro senza dover continuamente interagire col server remoto.
Ecco: git è ancora più estremo; preferisce farti avere a disposizione tutto sul tuo computer locale; non solo il singolo checkout, ma l’intera storia del progetto, dal primo all’ultimo commit.
In effetti, qualunque cosa tu voglia fare, git chiede normalmente di ottenere una copia completa di quel che è presente sul server remoto. Ma non preoccuparti troppo: git è più veloce a ottenere l’intera storia del progetto di quanto SVN lo sia ad ottenere un singolo checkout.
Il modello di storage¶
Passiamo alla terza differenza. E preparati a conoscere il vero motivo per cui git sta sostituendo molto velocemente SVN come nuovo standard de-facto.
- SVN memorizza la collezione dei vari delta applicati nel tempo ai file; all’occorrenza ricostruisce lo stato attuale;
- git memorizza i file così come sono, nella loro interezza; all’occorrenza ne calcola i delta.
Se vuoi evitare tanti grattacapi con git, il miglior suggerimento che tu possa seguire è di trattarlo come un database chiave/valore.
Passa al terminal e guarda nel concreto.
Mettiti nella condizione di avere 2 file vuoti sul file system:
mkdir progetto
cd progetto
mkdir libs
touch libs/foo.txt
mkdir templates
touch templates/bar.txt
/
├──libs
| └──foo.txt
|
├──templates
└──bar.txt
Decidiamo di gestire il progetto con git
git init
Aggiungi il primo file a git
git add libs/foo.txt
Con questo comando, git ispeziona il contenuto del file (è vuoto!) e lo memorizza nel suo database chiave/valore, chiamato Object Database e conservato su file system nella directory nascosta .git.
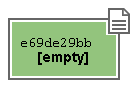
Siccome il blob-storage è un database chiave/valore, git cercherà di calcolare una chiave ed un valore per il file che hai aggiunto. Per il valore git userà il contenuto stesso del file; per la chiave, calcolerà lo SHA1 del contenuto (se sei curioso, nel caso di un file vuoto vale e69de29bb2d1d6434b8b29ae775ad8c2e48c5391)
Per cui, nell’Object Database git salverà un oggetto blob, univocamente identificabile dalla sua chiave (che, in assenza di ambiguità, vale la pena di abbreviare)
Adesso aggiungi il secondo file
git add templates/bar.txt
Ora, siccome libs/foo.txt e templates/bar.txt hanno lo stesso identico contenuto (sono entrambi vuoti!), nell’Object Database entrambi verranno conservati in un unico oggetto:
Come vedi, nell’Object Database git ha memorizzato solo il contenuto del file, non il suo nome né la sua posizione.
Naturalmente, però, a noi il nome dei file e la loro posizione interessano eccome. Per questo, nell’Object Database, git memorizza anche altri oggetti, chiamati tree che servono proprio a memorizzare il contenuto delle varie directory e i nomi dei file.
Nel nostro caso, avremo 3 tree
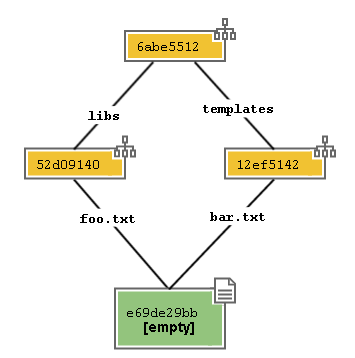
Come ogni altro oggetto, anche i tree sono memorizzati come oggetti chiave/valore.
Tutte queste strutture vengono raccolte dentro un contenitore, chiamato commit.
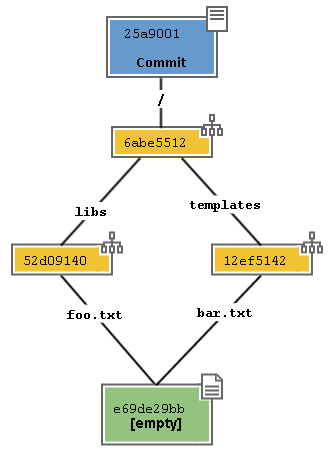
Come avrai intuito, un commit non è altro che un elemento del database chiave/valore, la cui chiave è uno SHA1, come per tutti gli altri oggetti, e il cui valore è un puntatore al tree del progetto, cioè la sua chiave (più un altro po’ di informazioni, come la data di creazione, il commento e l’autore). Non è troppo complicato, dopo tutto, no?
Quindi, il commit è l’attuale fotografia del file system.
Adesso fai
git commit -m "commit A, il mio primo commit"
Stai dicendo a git:
memorizza nel repository, cioè nella storia del progetto, il commit che ti ho preparato a colpi di add
Il tuo repository, visto da SmartGit, adesso ha questo aspetto
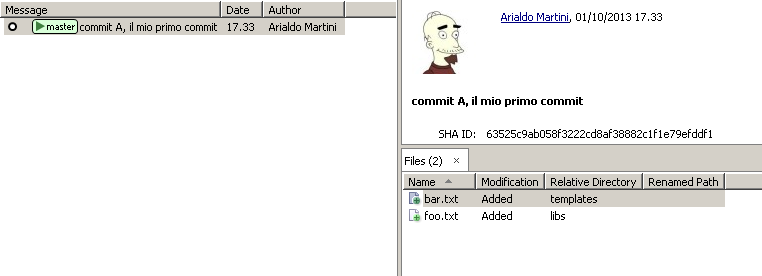
La riga col pallino che vedi sulla sinistra rappresenta l’oggetto commit. Nel pannello sulla destra, invece, puoi vedere la chiave del commit.
In generale, a meno che non si debba parlare proprio del modello interno, come stiamo facendo adesso, non c’è una grande necessità di rappresentare tutta la struttura di blob e tree che costituisce un commit. Difatti, dopo il prossimo paragrafo inizieremo a rappresentare i commit come nella figura qui sopra: con un semplice pallino.
Già da adesso, comunque, dovrebbe risultarti più chiaro il fatto che dentro un commit ci sia l’intera fotografia del progetto e che, di fatto, un commit sia l’unità minima ed indivisibile di lavoro.
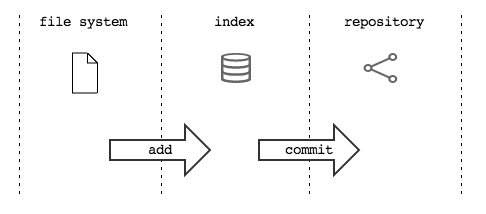
L’ index o staging area¶
Sostanzialmente, non c’è molto altro che tu debba sapere del modello di storage di git. Ma prima di passare a vedere i vari comandi, vorrei introdurti ad un altro meccanismo interno: la staging area o index. L’index risulta sempre misterioso a chi arriva da SVN: vale la pena parlarne perché, quando saprai come funzionano l’Object Database e l’index, git non ti sembrerà più contorto e incomprensibile; piuttosto, ne coglierai la coerenza e lo troverai estremamente prevedibile.
L’index è una struttura che fa da cuscinetto tra il file system e il repository. È un piccolo buffer che puoi utilizzare per costruire il prossimo commit.

Non è troppo complicato:
- il file system è la directory con i tuoi file.
- il repository è il database locale su file che conserva i vari commit
- l’index è lo spazio che git ti mette a disposizione per creare il tuo prossimo commit prima di registrarlo definitivamente nel repository
Fisicamente, l’index non è molto diverso dal repository: entrambi conservano i dati nell’Object Database, usando le strutture che hai visto prima.
In questo momento, appena dopo aver completato il tuo primo commit, l’index conserva una copia del tuo ultimo commit e si aspetta che tu lo modifichi.

Sul file system hai
/
├──libs
| └──foo.txt
|
├──templates
└──bar.txt
Proviamo a fare delle modifiche al file foo.txt
echo "nel mezzo del cammin" >> libs/foo.txt
e aggiorna l’index con
git add libs/foo.txt
Ecco un’altra differenza con svn: in svn add serve a mettere sotto versionamento un file e va eseguito una sola volta; in git serve a salvare un file dentro l’index ed è un’operazione che va ripetuta ad ogni commit.
All’esecuzione di git add git ripete quel che aveva già fatto prima: analizza il contenuto di libs/foo.txt, vede che c’è un contenuto che non ha mai registrato e quindi aggiunge all’Object Database un nuovo blob col nuovo contenuto del file; contestualmente, aggiorna il tree libs perché il puntatore chiamato foo.txt indirizzi il suo nuovo contenuto
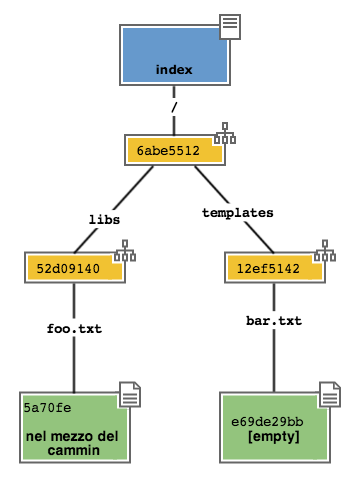
Prosegui aggiungendo un nuovo file doh.html alla root del progetto
echo "happy happy joy joy" > doh.html
git add doh.html
Come prima: git aggiunge un nuovo blob object col contenuto del file e, contestualmente, aggiunge nel tree “/” un nuovo puntatore chiamato doh.html che punta al nuovo blob object
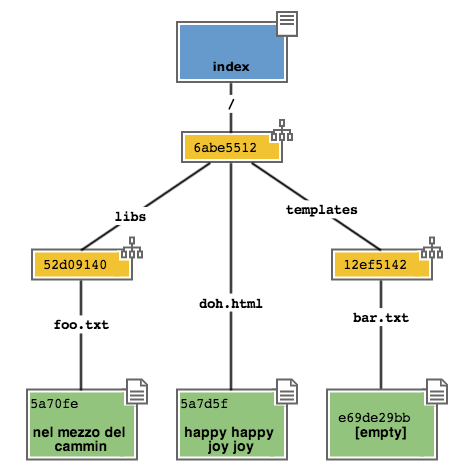
Il contenitore di tutta questa struttura è sempre un oggetto commit; git lo tiene parcheggiato nella staging area in attesa che tu lo spedisca al repository. Questa struttura rappresenta esattamente la nuova situazione sul file system: è nuovamente una fotografia dell’intero progetto, ed include anche il file bar.txt, nonostante tu non lo abbia modificato. Per inciso: non dovresti preoccuparti per il consumo di spazio perché, come vedi, per memorizzare bar.txt git sta riutilizzando l’oggetto blob creato nel commit precedente, per evitare duplicazioni.
Bene. Abbiamo quindi una nuova fotografia del progetto. A noi interessa, però, che git conservi anche la storia del nostro file system, per cui ci sarà bisogno di memorizzare da qualche parte il fatto che questa nuova situazione (lo stato attuale dell’index) sia figlia della precedente situazione (il precedente commit).
In effetti, git aggiunge automaticamente al commit parcheggiato nella staging area un puntatore al commit di provenienza
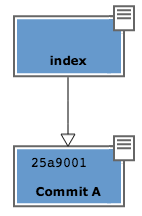
La freccia rappresenta il fatto che l’index è figlio del commit A. È un semplice puntatore. Nessuna sopresa, se ci pensi; git, dopo tutto, utilizza il solito, medesimo, semplicissimo modello ovunque: un database chiave/valore per conservare il dato, e una chiave come puntatore tra un elemento e l’altro.
Ok. Adesso committa
git commit -m "Commit B, Il mio secondo commit"
Con l’operazione di commit si dice a git “Ok, prendi l’attuale ``index`` e fallo diventare il tuo nuovo ``commit``. Poi restituiscimi l’``index`` così che possa fare una nuova modifica“
Dopo il commit nel database di git avrai
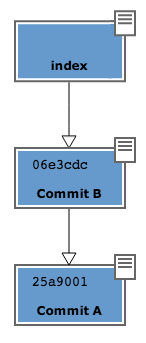
Una breve osservazione: spesso le interfacce grafiche di git omettono di visualizzare l’index. gitk, per esempio, la visualizza solo se ci sono modifiche da committare. Il tuo repository in gitk adesso viene visualizzato così

Guarda tu stesso. Lancia
gitk
Ricapitolando:
- git memorizza sempre i file nella loro interezza
- il commit è uno dei tanti oggetti conservati dentro il database chiave/valore di git. È un contenitore di tanti puntatori ad altri oggetti del database: i tree, che rappresentano directory, che a loro volta puntano ad altri tree (sotto-directory) o a dei blob (il contenuto dei file)
- ogni oggetto commit ha un puntatore al commit padre da cui deriva
- l’index è uno spazio di appoggio nel quale puoi costruire, a colpi di git add, il nuovo commit
- con git commit registri l’attuale index facendolo diventare il nuovo commit.
Bene: adesso hai tutta la teoria per capire i concetti più astrusi di git come il rebase, il cherrypick, l’octopus-merge, l’interactive rebase, il revert e il reset.
Passiamo al pratico.
![]()
get-git, una guida per capire git rapidamente e senza grattacapi
Ai miei colleghi di JobRapido
